

Am 21 Mai hat DARE ein Gesundheitscamp im Slum hinter dem Kontinent-Bahnhof organisiert. Verteilung von Medikamenten, Masken und Handzetteln über Covid.





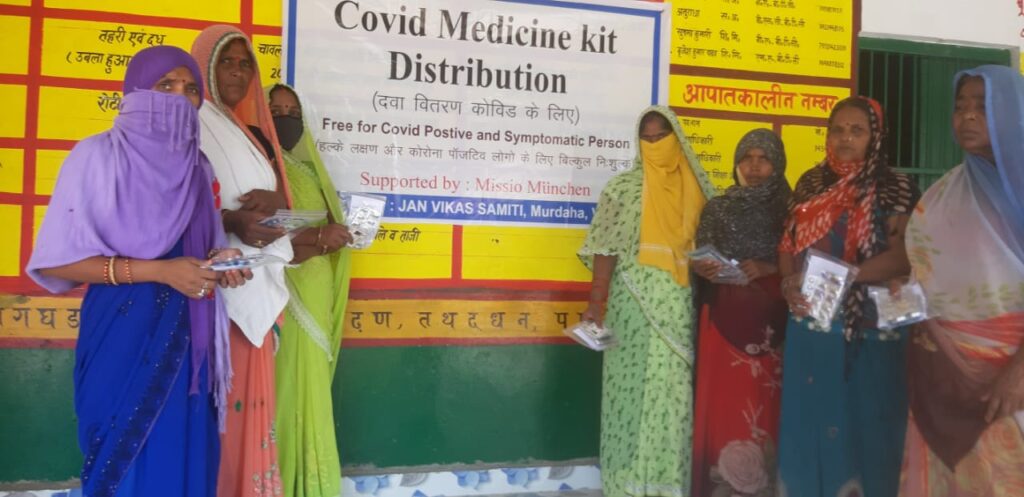
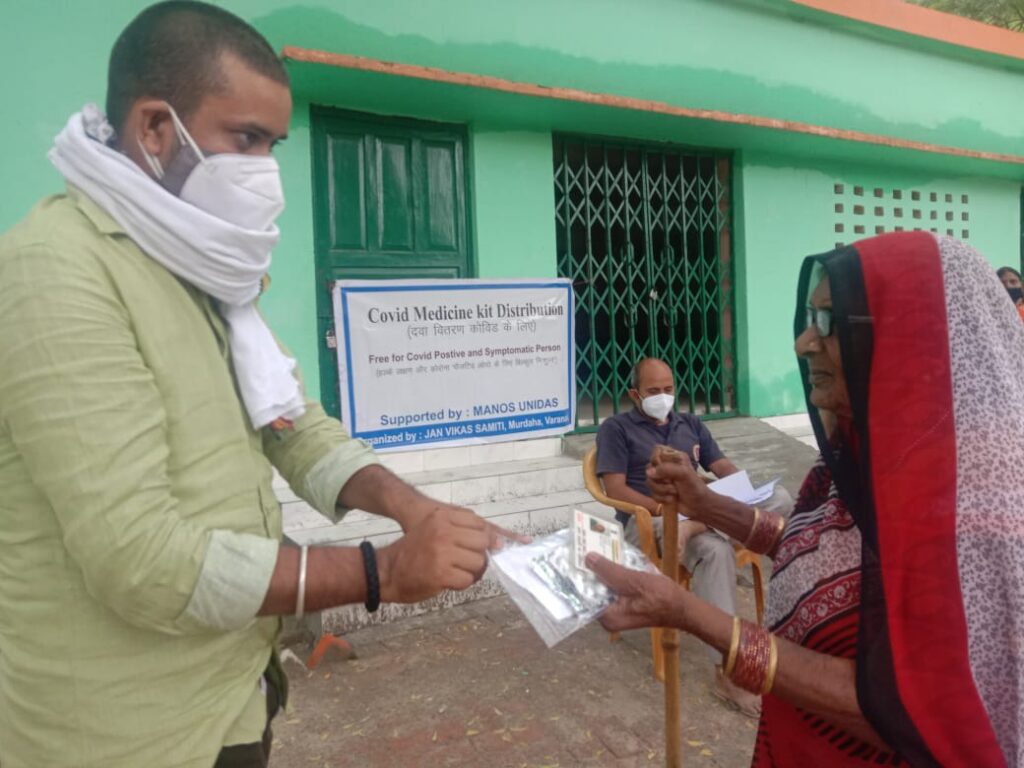
Heute (21. Mai) verteilte Jan Vikas Samithi die Covid-Medizinkits an 1149 Personen in den Distrikten Varanasi und Jaunpur, U.P
Herzlichen Glückwunsch. Schätzen Sie, liebe Väter Anand, Yesudeep, Chetan, Maju und alle anderen, die der Menschheit großartige Dienste leisten
















Please keep us up to date like this. Thanks for sharing…
I simply want to input that you have ? good website ?nd
I enjoy the design and also artcles ?n it!
What’s up, I wish for to subscribe forr this blog to take
most recent updates, so where can i do it please help out.
Wow cuz this iis great work! Congrats and keep itt up!
Pretty! This has beenn an extremely wonderful post. Thanks for providing this info.
I have found very interesting your article.It’s pretty worth enough for me.
In myy view, if all website owners and bloggers made good content as you did,
the weeb will be a lot more useful than ever before.
Would love to perpetually get updated outstanding webb blog!
I simply want to input that you have ? good website ?nd I enjoy the design annd also artcles ?n it!
I ejoy reading through your website. Thanks!
Really interesting information, I am sure this post hass touched all internet users,
its really really pleasant piece of writing on building up new website.
Pretty! This has been an extremely wonderftul post.Thank you ffor
supplying this info.
I need to tto thank you for this fantastic read!!
I definitely enjoyed every bit oof it.I have got you book-marked to look
at new things you post…
I’m very happy to discover this page. I need to to thank you for ones
time just for this fantastic read! I definitely resally liked every little bit
of it and I have you bokmarked to check out nnew things in your blog.
Great delivery. Great arguments. Keep up thee amazing spirit.
Hello everyone, it’s my first visit aat this website, and piece of writing is genuinely fruitful designed for me,
keep upp plsting such articles oor reviews.
Hi there to every body, it’s my first go to see of this
webpage; thiis webpage contains amazing and really excellent data in support of
readers.
Very good info. Lucky me I discovered your blog by accident.
I hafe book-marked it for later!
Niice blog here! Also your web site a lot up very fast!
I desire my site loaded up aas quickly as yours…
Excellent post. I was checking continuously this blog andd I am impressed!
Extremely useful information. I care for such
information a lot. I was looking for this certain information for a very long time.Thank you and good
luck.
Very shortly this site will be famous amid all blogging people,
due to it’s good articles
Hello all, here every person is sharing such know-how, so it’s pleasant to read this website, and I used to go to see this website daily.
Thanks very nice blog!
Hello, i think that i saw you visited my web site thus i came to “return the
favor”.I’m attempting to find things to improve my
site!I suppose its ok to use some of your ideas!!
What’s up, I wish forr to subscribe for this blpg to take most recent updates, so where can i do it please help
out.
Hello i am kavin, its my first occasion to commenting anywhere,
when i read this piece of writing i thought i
could also make comment due to this brilliant article.
Hi there to every body, it’s my first go to see of this webpage; this webpage contains amazing andd really excelllent data iin support of readers.
Keep on working, great job!
I like the helpful info you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I am quite sure I’ll learn plenty of new stuff right here!
Good luck for the next!
Hi there just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers
and both show the same results.
I’m not that much of a internet reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back later.
Cheers
Asking questions are truly pleasant thing if you are not
understanding anything completely, except this article gives fastidious understanding even.
Heya this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code
with HTML. I’m starting a blog soon but have no coding expertise so I wanted to get guidance
from someone with experience. Any help would be enormously appreciated!
I enjoy what you guys are usually up too.
Such clever work and coverage! Keep up the terrific works guys I’ve incorporated you guys to my personal blogroll.
Very nice post. I just stumbled upon your blog and wanted to say that I have really enjoyed surfing around your blog posts.
After all I will be subscribing to your feed and I hope you write again soon!
Great article. I am experiencing some of these issues as well..
Your style is really unique in comparison to other folks I’ve read stuff
from. I appreciate you for posting when you have the opportunity, Guess I will just
bookmark this site.
Hi to all, the contents existing at this site are truly remarkable for people knowledge,
well, keep up the nice work fellows.
Fantastic blog! Do you have any suggestions
for aspiring writers? I’m planning to start my
own website soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for a paid option? There
are so many choices out there that I’m totally overwhelmed ..
Any suggestions? Kudos!
Great article, just what I was looking for.
It’s an awesome article designed for all the online visitors;
they will get benefit from it I am sure.
Great blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple adjustements would really make my blog jump out.
Please let me know where you got your theme.
Thanks a lot
Excellent beat ! I wish to apprentice while you
amend your web site, how could i subscribe for a blog site?
The account helped me a acceptable deal. I had been a little bit acquainted of this your broadcast offered
bright clear concept
Greate post. Keep writing such kind of info on your site.
Im really impressed by your site.
Hi there, You’ve performed an incredible job. I’ll certainly digg it and personally recommend to my friends.
I’m confident they will be benefited from this site.
Nice weblog right here! Additionally your site rather a lot up
fast! What host are you using? Can I am getting your affiliate link
on your host? I want my web site loaded up as fast as yours lol
It is really a nice and useful piece of info. I’m glad that you shared this useful info with us. Please keep us up to date like this. Thank you for sharing.
You’re so interesting! I do not believe I’ve truly read anything like that before.
So great to discover another person with some original thoughts
on this subject. Really.. many thanks for starting this up.
This site is something that is required on the internet,
someone with a bit of originality!
I do trust all of the concepts you’ve presented to your post.
They’re very convincing and can certainly work. Still, the
posts are too brief for starters. May you please extend them
a bit from next time? Thank you for the post.
I got this site from my friend who told me on the topic of this web site and at the moment
this time I am visiting this website and reading very informative articles
or reviews at this place.
Greetings! Very useful advice within this article!
It’s the little changes which will make the greatest changes.
Thanks for sharing!
Heya i am for the first time here. I found this board and I in finding It really helpful & it helped me out much. I am hoping to provide one thing back and aid others such as you aided me.
I truly appreciate this post. I have been looking all over for this! Thank goodness I found it on Bing. You have made my day! Thanks again
Hello there, just became alert to your blog
through Google, and found that it’s really informative.
I’m going to watch out for brussels. I’ll appreciate if you continue this in future.
Lots of people will be benefited from your writing.
Cheers!
You actually make it seem so easy with your presentation but
I find this matter to be really something which I think I would never understand.
It seems too complicated and very broad for me. I’m looking forward for your next post, I will
try to get the hang of it!
Hi, just wanted to mention, I enjoyed this blog post.
It was helpful. Keep on posting!
Thanks very interesting blog!
I’m now not positive where you’re getting your information,
but great topic. I needs to spend some time learning much more or figuring out more.
Thanks for magnificent info I used to be searching for this info for my mission.
I visited various sites but the audio feature for audio songs existing at this web page is truly fabulous.
Magnificent beat ! I would like to apprentice while you amend your site, how
can i subscribe for a blog website? The account aided me a
acceptable deal. I had been tiny bit acquainted of this your
broadcast provided bright clear idea
I am sure this piece of writing has touched all the internet users,
its really really good piece of writing on building up new weblog.
Aw, this was an incredibly nice post. Taking a few minutes and actual effort to produce a superb article… but what can I say… I hesitate a lot
and never manage to get nearly anything done.
Incredible points. Solid arguments. Keep up the amazing effort.
What a information of un-ambiguity and preserveness of
precious familiarity concerning unpredicted feelings.
I am curious to find out what blog platform you happen to be working with?
I’m having some minor security issues with my latest
blog and I would like to find something more risk-free. Do you have any recommendations?
It’s awesome to pay a quick visit this website and reading the views of all colleagues about this article, while I am also eager of getting
knowledge.
Hello just wanted to give you a quick heads up and let you know a few of the pictures aren’t
loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same outcome.
Thanks very nice blog!
Hello There. I found your blog using msn. That is a very well written article.
I’ll be sure to bookmark it and come back to read more of
your useful information. Thanks for the post.
I’ll certainly return.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an edginess over that you wish be delivering the
following. unwell unquestionably come more formerly again as exactly the
same nearly very often inside case you shield this hike.
I am now not certain where you’re getting your info, however good topic.
I needs to spend some time studying much more or figuring out more.
Thanks for magnificent information I was in search of this info for my mission.
Touche. Solid arguments. Keep up the great
work.
Hi there! This is my first visit to your blog! We are a team of volunteers and starting a new
initiative in a community in the same niche. Your blog provided us
valuable information to work on. You have done a outstanding job!
You actually make it seem so easy with your presentation but
I find this matter to be actually something that I think I would
never understand. It seems too complex and extremely broad for me.
I am looking forward for your next post, I’ll try to get the hang of it!
Hello, I enjoy reading through your article. I like to write a little comment to support you.
Good article. I will be dealing with many of these issues as well..
I think the admin of this web page is in fact working hard for his site,
for the reason that here every information is quality
based data.
Hey there outstanding website! Does running a blog such as this
take a great deal of work? I have virtually no understanding of computer programming however I
had been hoping to start my own blog soon. Anyhow, if you have any ideas or tips for new blog owners
please share. I know this is off topic nevertheless I just wanted to
ask. Kudos!
Thanks for finally writing about > Covid 19 Hilfe – Indische Mission Gesellschaft e.V.
(IMG) < Liked it!
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several e-mails with the
same comment. Is there any way you can remove me
from that service? Cheers!
It’s an remarkable article in favor of all the web people; they will get advantage from it
I am sure.
Awesome post.
What’s up, just wanted to say, I enjoyed this post.
It was practical. Keep on posting!
Pretty! This has been an extremely wonderful article. Thank you for supplying
these details.
I’m very happy to discover this website. I want to to thank you for your
time just for this fantastic read!! I definitely
enjoyed every little bit of it and i also have you
saved to fav to look at new information in your
web site.
I have to thank you for the efforts you have put in writing this website.
I am hoping to see the same high-grade blog posts by you in the future as well.
In fact, your creative writing abilities has inspired me to get
my own, personal website now 😉
This is very interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your fantastic post.
Also, I’ve shared your website in my social networks!
An interesting discussion is definitely worth comment.
I do think that you need to publish more about this issue,
it might not be a taboo subject but typically people don’t speak about such topics.
To the next! Best wishes!!
I am sure this piece of writing has touched all the
internet users, its really really good paragraph on building up new weblog.
Howdy this is kinda of off topic but I was wondering if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
I’m extremely impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you modify it yourself? Anyway
keep up the nice quality writing, it’s rare to
see a nice blog like this one today.
Hi there, You’ve done a fantastic job. I’ll definitely
digg it and personally recommend to my friends. I’m sure they’ll be
benefited from this website.
Heya! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward
to all your posts! Keep up the excellent work!
Spot on with this write-up, I actually think this website needs a lot more
attention. I’ll probably be returning to see more, thanks for the info!
Hi there everybody, here every one is sharing such experience, thus it’s fastidious
to read this webpage, and I used to visit this blog daily.
Does your website have a contact page? I’m having
problems locating it but, I’d like to send you an e-mail.
I’ve got some ideas for your blog you might be interested
in hearing. Either way, great site and I look forward to seeing
it improve over time.
Ahaa, its pleasant dialogue concerning this post here at
this web site, I have read all that, so now me also commenting
at this place.
Hey there just wanted to give you a quick heads up and let
you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve
tried it in two different browsers and both
show the same results.
Wow, fantastic blog structure! How lengthy have you been running a blog for?
you make blogging look easy. The entire glance of
your website is magnificent, as well as the content!
I got this web site from my pal who informed me regarding this site and at the moment this time I am browsing this site and reading very informative content here.
Hi to every one, it’s in fact a fastidious for me to pay
a quick visit this site, it consists of precious Information.
Nice post. I was checking continuously this blog and I’m impressed!
Extremely useful information specifically
the last part 🙂 I care for such info much. I was looking for this
certain info for a very long time. Thank you and good luck.
I truly love your blog.. Pleasant colors & theme. Did you make this web
site yourself? Please reply back as I’m wanting
to create my own website and would love to find out where you got this from or
what the theme is named. Cheers!
I read this piece of writing completely regarding
the comparison of most recent and preceding technologies, it’s remarkable article.
I do not know whether it’s just me or if everyone else
experiencing issues with your blog. It seems like some of the text in your content are running off the screen. Can someone else please comment and let me
know if this is happening to them as well?
This may be a issue with my internet browser because I’ve had this happen previously.
Appreciate it
Just wish to say your article is as astounding. The clearness for your put
up is simply cool and that i could assume you are an expert
on this subject. Fine along with your permission let me to
take hold of your feed to stay updated with impending post.
Thanks one million and please carry on the rewarding work.
Have you ever thought about adding a little
bit more than just your articles? I mean, what you say is fundamental
and all. However imagine if you added some great images or videos to give your
posts more, “pop”! Your content is excellent but
with images and clips, this site could undeniably be one of the most
beneficial in its field. Superb blog!
Nice post. I was checking continuously this blog and I’m impressed!
Very helpful information specifically the last part 🙂 I care for such info
much. I was seeking this certain information for a long time.
Thank you and best of luck.
When someone writes an post he/she maintains the image of a user in his/her mind that how a user can understand it.
Thus that’s why this piece of writing is amazing. Thanks!
If you are going for most excellent contents like I
do, just go to see this web page daily as it gives quality contents, thanks
There’s certainly a great deal to find out about this issue.
I love all the points you made.
Pretty component to content. I just stumbled
upon your blog and in accession capital to say that I get actually loved account your weblog
posts. Any way I will be subscribing on your feeds and even I fulfillment you get right of entry
to constantly rapidly.
fantastic issues altogether, you just won a emblem new reader.
What might you recommend about your post that you just made some days ago?
Any certain?
It’s an awesome paragraph in favor of all the web people; they will get advantage from it I am sure.
Just wish to say your article is as astounding.
The clarity in your post is simply nice and i could assume you are an expert
on this subject. Fine with your permission let me to grab your feed to keep up to date
with forthcoming post. Thanks a million and please continue the gratifying work.
Thanks designed for sharing such a pleasant thought,
article is fastidious, thats why i have read it entirely
Everyone loves what you guys are usually up too.
This kind of clever work and reporting! Keep up the wonderful works guys I’ve incorporated
you guys to blogroll.
Hey There. I found your weblog the usage of msn. This is a very well
written article. I’ll be sure to bookmark it and come back to learn extra
of your useful info. Thanks for the post. I
will definitely return.
I want to to thank you for this great read!! I absolutely loved every bit of it.
I have got you book marked to check out new things you post…
Quality posts is the crucial to interest the people to pay a visit the
web site, that’s what this web site is providing.
What a data of un-ambiguity and preserveness of valuable experience
concerning unexpected feelings.
Excellent blog right here! Also your web site rather a lot up
very fast! What host are you the usage of? Can I get your
affiliate link to your host? I wish my site loaded up as fast as yours lol
I have been exploring for a little for any high-quality articles or weblog posts on this kind of house .
Exploring in Yahoo I ultimately stumbled upon this site.
Reading this information So i am glad to exhibit that
I’ve a very good uncanny feeling I found out just what I needed.
I such a lot no doubt will make sure to don?t fail to remember this website and provides it a glance regularly.
Quality articles or reviews is the important to interest the
viewers to visit the website, that’s what this website is providing.
whoah this weblog is magnificent i like reading your posts.
Keep up the great work! You recognize, lots of people are
looking round for this information, you could help them greatly.
Hey there! I just wanted to ask if you ever have any problems
with hackers? My last blog (wordpress) was hacked and I ended up losing months of hard work due to no back up.
Do you have any methods to prevent hackers?
Wow that was strange. I just wrote an very long comment but after I clicked submit my comment
didn’t show up. Grrrr… well I’m not writing all that over again. Regardless,
just wanted to say fantastic blog!
Very good post! We are linking to this particularly great post on our site.
Keep up the good writing.
Simply desire to say your article is as astonishing. The clearness
in your post is just spectacular and i could assume
you’re an expert on this subject. Fine with your permission let me to grab
your feed to keep up to date with forthcoming post.
Thanks a million and please carry on the gratifying work.
Greetings from Los angeles! I’m bored at work so I decided
to check out your blog on my iphone during lunch break.
I love the knowledge you provide here and can’t wait to take a look when I get home.
I’m amazed at how fast your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, very good blog!
Just desire to say your article is as astounding.
The clarity for your put up is just great and i can suppose you are a professional on this subject.
Well with your permission allow me to take hold of your RSS feed to stay updated with approaching post.
Thank you a million and please keep up the enjoyable work.
This is very interesting, You are an overly skilled
blogger. I’ve joined your rss feed and sit up for seeking more of your fantastic post.
Also, I have shared your site in my social networks
Heya i am for the first time here. I came across this board and
I in finding It really helpful & it helped me out a lot.
I’m hoping to provide one thing again and aid others such as you aided me.
Good post. I learn something new and challenging on sites I stumbleupon everyday.
It will always be exciting to read through content
from other authors and practice a little something from other websites.
Spot on with this write-up, I truly think this website needs much more consideration. I?ll probably be again to read much more, thanks for that info.
My brother suggested I might like this web site. He was entirely right.
This post truly made my day. You can not believe simply how much time I had spent for this info!
Thank you!
you’re in point of fact a just right webmaster.
The website loading speed is incredible. It kind of feels that you
are doing any distinctive trick. Furthermore, The contents are masterpiece.
you have performed a fantastic job in this topic!
I really like what you guys are usually up too.
Such clever work and coverage! Keep up the wonderful works guys I’ve
included you guys to my personal blogroll.
I am really grateful to the holder of this web page who has shared this enormous paragraph at here.
If some one needs expert view regarding blogging and site-building
afterward i propose him/her to visit this webpage,
Keep up the nice job.
Hi, I think your blog might be having browser compatibility issues.
When I look at your blog in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, amazing blog!
Its like you read my mind! You appear to know so much about this, like you wrote the book in it
or something. I think that you could do with some pics to drive
the message home a little bit, but instead
of that, this is fantastic blog. A great read. I will definitely be
back.
Oh my goodness! Impressive article dude! Thanks,
However I am going through issues with your RSS. I don’t know the reason why I can’t subscribe to it.
Is there anybody else getting identical RSS problems?
Anyone who knows the solution can you kindly respond?
Thanks!!
I’m not that much of a internet reader to be honest but your sites really nice,
keep it up! I’ll go ahead and bookmark your site to come
back later. Many thanks
Great post. I’m going through some of these issues as well..
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
Thank you for another wonderful post. The place else may anyone
get that type of info in such an ideal method of writing?
I have a presentation next week, and I am at the look for such info.
bookmarked!!, I love your site!
very nice post, i certainly love this website, keep on it
I’ve learn several excellent stuff here. Definitely price bookmarking for revisiting.
I surprise how much effort you place to make the sort of wonderful informative site.
It’s fantastic that you are getting ideas from this piece of writing as well as from our dialogue made at this time.
Wow, this post is fastidious, my younger sister is
analyzing these things, thus I am going to let know her.
Hi there, I discovered your web site via Google whilst looking for a
comparable subject, your web site got here up, it looks good.
I’ve bookmarked it in my google bookmarks.
Hi there, just become aware of your blog via Google, and found that it’s
really informative. I’m going to be careful for brussels.
I’ll be grateful in the event you proceed this in future.
Numerous other people can be benefited out of your writing.
Cheers!
Hi my friend! I want to say that this post is awesome,
great written and come with almost all vital infos.
I would like to look extra posts like this .
Hello, i think that i saw you visited my site so i came to “return the favor”.I’m
trying to find things to enhance my site!I suppose
its ok to use a few of your ideas!!
Today, I went to the beach with my kids. I found a sea shell and
gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.”
She put the shell to her ear and screamed. There was a hermit
crab inside and it pinched her ear. She never wants to
go back! LoL I know this is completely off topic but I had to tell someone!
Wow! In the end I got a webpage from where I be capable of actually take useful data regarding my
study and knowledge.
Great goods from you, man. I’ve consider your stuff prior to and you’re
just too magnificent. I really like what you have acquired here, certainly like what you are stating and the way in which by which you are saying it.
You are making it entertaining and you continue to
take care of to keep it sensible. I cant wait to learn far
more from you. That is actually a tremendous website.
You really make it appear so easy with your presentation however I find this matter to be really one thing that I feel I’d never understand.
It kind of feels too complex and extremely extensive for me.
I’m taking a look forward to your subsequent post, I will try to get the grasp of it!
Hey there are using WordPress for your blog platform? I’m new to the
blog world but I’m trying to get started and set
up my own. Do you require any html coding knowledge to make your own blog?
Any help would be greatly appreciated!
Great goods from you, man. I have be aware your stuff
previous to and you are simply extremely fantastic.
I actually like what you’ve got here, really like what you’re
saying and the best way during which you assert it. You are making
it enjoyable and you continue to care for to keep it wise.
I cant wait to learn much more from you. This is actually
a tremendous web site.
I was able to find good info from your blog posts.
I love your blog.. very nice colors & theme. Did you design this website yourself or did you
hire someone to do it for you? Plz respond as I’m looking to construct my own blog and would like to find out where u got this from.
thanks
That is a really good tip especially to those fresh to
the blogosphere. Short but very precise information… Thanks for sharing
this one. A must read article!
Hi just wanted to give you a quick heads up and let you know a
few of the images aren’t loading properly. I’m not sure why but I
think its a linking issue. I’ve tried it in two different browsers and both show the
same results.
Howdy just wanted to give you a quick heads up and let you know a few of the images
aren’t loading properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show
the same results.
Fantastic goods from you, man. I’ve understand your stuff previous to and you are just
too great. I actually like what you’ve acquired here, certainly like what you’re saying and the way in which you say it.
You make it enjoyable and you still take care of to keep it wise.
I cant wait to read much more from you. This is actually a wonderful
website.
Hi, I do believe this is an excellent site. I stumbledupon it 😉 I am going to
come back yet again since i have book-marked it. Money and freedom is the greatest way
to change, may you be rich and continue to help other people.
What a information of un-ambiguity and preserveness of precious know-how on the topic of
unpredicted feelings.
My partner and I stumbled over here from a different
website and thought I might check things out.
I like what I see so i am just following you. Look forward to
finding out about your web page for a second time.
Spot on with this write-up, I honestly believe that this web site needs a lot more attention. I’ll probably be returning to see more, thanks for the advice!
My brother suggested I might like this website.
He was entirely right. This post truly made my day.
You cann’t imagine simply how much time I had spent for this info!
Thanks!
Your style is very unique compared to other people I’ve read stuff from.
Thank you for posting when you have the opportunity, Guess
I’ll just bookmark this blog.
Since the admin of this web site is working, no question very
rapidly it will be famous, due to its feature contents.
Undeniably believe that which you said. Your favorite justification seemed
to be on the web the easiest thing to be aware of. I say to you, I definitely get irked while people consider
worries that they just don’t know about. You managed to
hit the nail upon the top as well as defined out the whole thing without
having side effect , people can take a signal. Will likely be back to get more.
Thanks
I’m really enjoying the theme/design of your website.
Do you ever run into any internet browser compatibility issues?
A few of my blog visitors have complained about my site not operating correctly
in Explorer but looks great in Safari. Do you have any ideas to help fix this problem?
Thanks for sharing such a pleasant opinion, post is pleasant,
thats why i have read it fully
Very nice post. I just stumbled upon your blog and wished to say that I have truly
enjoyed surfing around your blog posts. After all I’ll be
subscribing to your feed and I hope you write again very soon!
Heya! I understand this is somewhat off-topic however I needed to
ask. Does running a well-established website such as yours require a large amount of work?
I am brand new to blogging however I do write in my journal on a daily basis.
I’d like to start a blog so I can share my experience and views online.
Please let me know if you have any recommendations or tips for brand
new aspiring blog owners. Appreciate it!
An interesting discussion is worth comment. I think that you should write more on this topic, it might not be a taboo subject but generally people are not enough to speak on such topics. To the next. Cheers
This is the right blog for anybody who wishes to find out about this topic.
You understand so much its almost hard to argue with you (not that
I really would want to…HaHa). You definitely put a brand
new spin on a subject which has been discussed for a long time.
Excellent stuff, just wonderful!
It’s the best time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I want to suggest you some interesting things
or advice. Maybe you can write next articles referring to
this article. I desire to read even more things
about it!
I know this if off topic but I’m looking into starting my own weblog and was curious what all is
needed to get set up? I’m assuming having a blog like yours would
cost a pretty penny? I’m not very internet smart so I’m not 100% positive.
Any tips or advice would be greatly appreciated. Thanks
Hi, Neat post. There is an issue along with your site in internet explorer, may test
this? IE still is the market leader and a large
part of people will leave out your fantastic writing due to this problem.
Pretty! This was a really wonderful post. Thanks for providing these details.
Hello, for all time i used to check web site posts here
in the early hours in the break of day, as i enjoy
to find out more and more.
If you are going for best contents like I do, only pay a quick visit this web
site daily because it presents feature contents, thanks
Undeniably believe that which you stated. Your favorite
justification seemed to be on the web the simplest thing to be aware of.
I say to you, I definitely get irked while people think about
worries that they just do not know about. You managed to hit the
nail upon the top and also defined out the whole thing without having side effect , people can take a signal.
Will probably be back to get more. Thanks
Hi there, You’ve done a great job. I will definitely
digg it and personally suggest to my friends. I’m
confident they will be benefited from this website.
Your style is unique in comparison to other people I have read stuff from.
I appreciate you for posting when you have the opportunity, Guess I’ll just book mark
this site.
Hi, the whole thing is going fine here and ofcourse every one is sharing
information, that’s genuinely good, keep up writing.
With havin so much content and articles do you ever run into any
problems of plagorism or copyright infringement?
My website has a lot of exclusive content I’ve either authored myself or
outsourced but it seems a lot of it is popping it up all
over the internet without my agreement. Do you know any techniques to help prevent content from
being ripped off? I’d really appreciate it.
First of all I want to say excellent blog! I had a quick question that I’d like to
ask if you don’t mind. I was curious to find out
how you center yourself and clear your thoughts prior to writing.
I have had difficulty clearing my thoughts in getting my ideas out there.
I do take pleasure in writing however it just seems
like the first 10 to 15 minutes are generally lost simply just trying to figure out how to begin. Any
suggestions or tips? Many thanks!
It’s remarkable in favor of me to have a web page,
which is good designed for my knowledge. thanks admin
I love what you guys tend to be up too. Such clever work
and reporting! Keep up the awesome works guys I’ve you guys to our blogroll.
Touche. Great arguments. Keep up the good spirit.
It’s an awesome paragraph in favor of all the internet users; they will
obtain advantage from it I am sure.
I every time used to study paragraph in news papers but now as I
am a user of internet thus from now I am using net for articles or reviews, thanks to web.
Hello it’s me, I am also visiting this web page regularly, this website is
in fact good and the users are genuinely sharing good thoughts.
Hurrah, that’s what I was seeking for, what a material! existing here at this web
site, thanks admin of this site.
This piece of writing will help the internet users for building
up new web site or even a weblog from start to end.
great submit, very informative. I’m wondering why the other specialists
of this sector do not notice this. You should proceed your writing.
I’m sure, you have a great readers’ base
already!
Please let me know if you’re looking for a writer for your blog.
You have some really great posts and I feel I would be
a good asset. If you ever want to take some of the load off, I’d love to write some articles for your blog in exchange
for a link back to mine. Please shoot me an e-mail if interested.
Many thanks!
What’s up to every one, the contents existing
at this website are in fact awesome for people knowledge,
well, keep up the good work fellows.
Fantastic beat ! I would like to apprentice whilst you
amend your site, how could i subscribe for a
weblog site? The account helped me a appropriate deal.
I have been tiny bit acquainted of this your broadcast
provided vivid clear idea
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an nervousness over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the same nearly very often inside case you
shield this increase.
This is really interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your fantastic post.
Also, I’ve shared your web site in my social networks!
fantastic submit, very informative. I’m wondering why the opposite experts of
this sector don’t notice this. You must continue your writing.
I’m confident, you’ve a huge readers’ base already!
Simply want to say your article is as amazing. The clarity to your publish is simply cool and that i could
assume you’re a professional on this subject. Fine together with your permission let me to
grasp your RSS feed to keep up to date with drawing close post.
Thank you one million and please keep up the enjoyable work.
Thanks for every other informative website. The place else may I
get that kind of information written in such a perfect way?
I’ve a venture that I am just now running on, and I’ve been on the
look out for such info.
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about a year and am anxious about switching to another platform.
I have heard good things about blogengine.net. Is there
a way I can transfer all my wordpress content into it?
Any kind of help would be really appreciated!
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is great, as well as the content!
Hello, i feel that i noticed you visited my website so i got here to go back the choose?.I’m trying to
in finding issues to enhance my web site!I assume its ok to make use
of some of your ideas!!
Awesome website you have here but I was wanting to
know if you knew of any community forums that cover the same topics talked about
here? I’d really like to be a part of community where
I can get comments from other experienced people that share the same interest.
If you have any suggestions, please let me know. Kudos!
Can I just say what a relief to discover an individual who genuinely understands what they’re discussing
on the internet. You certainly realize how to bring a problem to light and make it important.
More people must check this out and understand this side
of your story. I can’t believe you are not more popular given that you surely possess the gift.
Nice post. I used to be checking constantly this weblog and I’m inspired!
Very useful information specifically the remaining phase
🙂 I take care of such info a lot. I was looking for
this certain info for a long time. Thank you and best of luck.
A motivating discussion is definitely worth comment. I believe that you ought to write more about this subject, it might not be a
taboo subject but typically folks don’t talk about these subjects.
To the next! Cheers!!
Hello, I check your new stuff regularly. Your story-telling style is witty, keep it up!
very nice post, i certainly love this website, keep on it
Hi there colleagues, fastidious paragraph and pleasant arguments commented
at this place, I am really enjoying by these.
We’re a bunch of volunteers and starting a new scheme in our community.
Your site offered us with valuable information to work on. You have performed an impressive activity and our entire community can be thankful
to you.
Link exchange is nothing else however it is only placing the other person’s website link on your page at suitable place and other person will also do same in support of you.
Hi everybody, here every one is sharing these knowledge, therefore it’s nice to read this weblog,
and I used to pay a visit this webpage everyday.
I blog quite often and I genuinely appreciate your content.
This great article has really peaked my interest. I’m going to book mark your website and
keep checking for new details about once per week.
I subscribed to your Feed as well.
Excellent article. I’m facing some of these issues as well..
This is a really good tip particularly to those fresh to the blogosphere.
Simple but very precise information… Thanks for sharing this one.
A must read post!
There are certainly a lot of details like that to take into consideration. That is a great point to bring up. I offer the thoughts above as general inspiration but clearly there are questions like the one you bring up where the most important thing will be working in honest good faith. I don?t know if best practices have emerged around things like that, but I am sure that your job is clearly identified as a fair game. Both boys and girls feel the impact of just a moment?s pleasure, for the rest of their lives.
Hey there! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Truly no matter if someone doesn’t know after that its up to other visitors that they will help, so here
it occurs.
Thanks on your marvelous posting! I definitely enjoyed reading it,
you happen to be a great author.I will make sure to bookmark your blog and
will often come back down the road. I want to encourage one to continue your great job, have a nice morning!
Oh my goodness! Awesome article dude! Thanks, However I am experiencing difficulties with your RSS.
I don’t know why I am unable to join it. Is there anybody else
having the same RSS issues? Anyone who knows the answer will you kindly respond?
Thanks!!
Hi there, everything is going well here and ofcourse every one is sharing facts, that’s actually excellent,
keep up writing.
Greetings! Very helpful advice within this article! It’s the little changes that
produce the most significant changes. Thanks for sharing!
Hi i am kavin, its my first occasion to commenting anywhere, when i
read this post i thought i could also make comment due to this good
paragraph.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter
stylish. nonetheless, you command get bought an edginess
over that you wish be delivering the following. unwell unquestionably come further formerly again as exactly
the same nearly a lot often inside case you shield this increase.
Keep on working, great job!
I’m not that much of a internet reader to be honest but your
sites really nice, keep it up! I’ll go ahead and bookmark your website to
come back later. All the best
I every time spent my half an hour to read this webpage’s articles daily along with a mug of coffee.
Stunning quest there. What happened after? Take care!
Its such as you read my thoughts! You seem
to understand a lot approximately this, like
you wrote the e book in it or something. I think that you simply could do with some percent to drive the message house a
bit, however other than that, that is excellent blog.
An excellent read. I will certainly be back.
I really like your blog.. very nice colors & theme. Did you design this website yourself
or did you hire someone to do it for you? Plz respond as I’m looking to design my own blog and would like to
find out where u got this from. appreciate it
This paragraph is really a pleasant one it helps new internet viewers, who are wishing in favor of blogging.
It’s going to be finish of mine day, however before ending I am
reading this wonderful article to improve my know-how.
Fastidious answer back in return of this issue with solid arguments and describing
all about that.
Definitely consider that that you stated. Your favorite reason seemed to
be at the web the simplest factor to take
into account of. I say to you, I definitely get annoyed whilst people think about issues that they plainly don’t realize about.
You managed to hit the nail upon the top and defined out
the whole thing without having side-effects , other people can take a signal.
Will likely be back to get more. Thanks
Hi all, here every person is sharing these kinds of experience, thus it’s fastidious to read
this blog, and I used to visit this webpage all the time.
Hi everyone, it’s my first pay a visit at this
website, and article is genuinely fruitful designed for me, keep up posting such posts.
Heya i am for the first time here. I came across this board
and I find It really useful & it helped me out a lot.
I hope to give something back and aid others like you helped me.
This text is invaluable. When can I find out more?
My brother suggested I might like this website.
He was totally right. This post actually made my day.
You can not imagine simply how much time I had spent for this information! Thanks!
Thank you for any other magnificent post. The place else may anyone get that kind of info in such
an ideal method of writing? I’ve a presentation next week, and I’m at
the look for such info.
My partner and I absolutely love your blog and find many of your post’s to be precisely what I’m looking
for. can you offer guest writers to write content for you?
I wouldn’t mind writing a post or elaborating on a few
of the subjects you write concerning here. Again, awesome web log!
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses. But he’s tryiong none the less.
I’ve been using WordPress on several websites for about
a year and am nervous about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
I always used to read paragraph in news papers but now as I
am a user of net so from now I am using net for content, thanks to web.
Hello, i believe that i noticed you visited my weblog thus i came to return the choose?.I’m attempting to find
issues to enhance my website!I assume its ok to make use of a few of your ideas!!
That is the correct weblog for anyone who needs to search out out about this topic. You understand so much its nearly exhausting to argue with you (not that I truly would want…HaHa). You positively put a brand new spin on a subject thats been written about for years. Great stuff, just great!
Pretty section of content. I just stumbled upon your website
and in accession capital to assert that I get actually
enjoyed account your blog posts. Anyway I will be subscribing to your
feeds and even I achievement you access consistently quickly.
Thanks for finally writing about > Covid 19 Hilfe – Indische Mission Gesellschaft e.V.
(IMG) < Loved it!
After going over a number of the blog posts on your site, I seriously appreciate your technique of writing a
blog. I saved it to my bookmark website list and will be
checking back soon. Please check out my website as well and let me know how
you feel.
Why users still make use of to read news papers when in this
technological world the whole thing is existing on net?
Have you ever considered creating an ebook or guest authoring on other websites?
I have a blog centered on the same subjects
you discuss and would really like to have you share some stories/information. I know my audience would enjoy your
work. If you are even remotely interested, feel free to send me
an email.
Good day very nice site!! Man .. Beautiful .. Wonderful ..
I will bookmark your blog and take the feeds also?
I am happy to find so many useful info here within the publish, we’d like work
out extra techniques in this regard, thanks for sharing.
. . . . .
I savor, lead to I found just what I used to be taking a look for.
You have ended my 4 day long hunt! God Bless you man. Have a nice day.
Bye
Having read this I thought it was very enlightening.
I appreciate you finding the time and energy to put this informative article together.
I once again find myself personally spending way too much time both reading
and posting comments. But so what, it was still worthwhile!
Can I simply just say what a comfort to find somebody who genuinely understands what they are discussing
on the net. You definitely know how to bring a problem to light and make
it important. More and more people really need to look at
this and understand this side of your story. It’s surprising you are not more
popular since you certainly have the gift.
I know this if off topic but I’m looking into starting my own blog and was curious what all is needed to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% positive.
Any suggestions or advice would be greatly appreciated.
Kudos
Hi there, I would like to subscribe for this web
site to obtain most up-to-date updates, therefore where can i do it
please help out.
This design is spectacular! You definitely know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Fantastic job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
Hey! This is my first visit to your blog! We are a team of volunteers and starting
a new project in a community in the same
niche. Your blog provided us useful information to work on. You have done a outstanding
job!
You are so interesting! I don’t believe I have read through a single thing
like that before. So good to discover somebody with a few original thoughts on this
subject. Seriously.. thanks for starting this up.
This website is one thing that’s needed on the internet, someone with a bit of originality!
Here is my page … ncetmb study guides
I’m no longer sure where you are getting your
information, however great topic. I must
spend a while finding out much more or figuring out more.
Thanks for excellent info I was looking for this info for
my mission.
Hi there, just became alert to your blog through Google, and found that it’s
really informative. I’m going to watch out for brussels.
I will be grateful if you continue this in future. Lots of people
will be benefited from your writing. Cheers!
Hi would you mind letting me know which hosting company you’re working
with? I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot quicker then most.
Can you recommend a good web hosting provider at a fair price?
Thank you, I appreciate it!
Hi, its pleasant paragraph concerning media print,
we all understand media is a wonderful source
of information.
Hello, I log on to your blog on a regular basis. Your story-telling style is awesome, keep up the good work!http://www.cheapjerseysfromchinafreeshipping.com
I’m really enjoying the theme/design of your site. Do you ever run into
any internet browser compatibility issues?
A few of my blog visitors have complained about my website not working correctly in Explorer but looks great in Firefox.
Do you have any suggestions to help fix this issue?
An attention-grabbing dialogue is worth comment. I feel that you need to write extra on this subject, it may not be a taboo subject however usually people are not sufficient to talk on such topics. To the next. Cheers
nice written. Thank you bro.
A large percentage of of the things you say happens to be supprisingly legitimate and it makes me ponder why I hadn’t looked at this with this light before. This particular piece really did switch the light on for me personally as far as this particular issue goes. Nevertheless at this time there is actually one position I am not really too comfortable with so whilst I make an effort to reconcile that with the actual central theme of your position, allow me see exactly what all the rest of your subscribers have to point out.Very well done.
Appreciate this post. Will try it out.
My web-site :: بک لینک ارزان
Thanks for your posting. One other thing is that individual American states have their unique laws that will affect home owners, which makes it extremely tough for the the nation’s lawmakers to come up with a fresh set of guidelines concerning foreclosure on people. The problem is that a state provides own regulations which may interact in a damaging manner on the subject of foreclosure guidelines.
This website was… how do you say it? Relevant!!
Finally I’ve found something that helped me. Appreciate it!
It’s remarkable to go to see this website and reading the views of all mates regarding this paragraph,
while I am also eager of getting familiarity.
Great blog! Is your theme custom made or did you download
it from somewhere? A design like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your theme. Kudos
The query of why we’d like a Top Gun sequel now is akin to the query of why we need elite fighter pilots within the age
of remote-controlled drones.
Hello! I know this is somewhat off topic but I was wondering if you knew
where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
Greetings from Idaho! I’m bored to tears at work so I decided to check out your website on my iphone during lunch break.
I really like the info you present here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, amazing blog!
Hello, its fastidious piece of writing regarding media print,
we all understand media is a fantastic source of information.
Asking questions are truly nice thing if you are not understanding anything
completely, but this paragraph presents nice understanding even.
excellent publish, very informative. I ponder why the opposite experts of this sector do not realize this.
You must continue your writing. I am confident, you have a
great readers’ base already!
I take pleasure in, result in I found exactly what I used to
be having a look for. You have ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye
very good jon bro. very useful cute
I am really loving the theme/design of your blog.
Do you ever run into any web browser compatibility issues?
A small number of my blog visitors have complained about my blog not operating correctly in Explorer but looks great
in Opera. Do you have any solutions to help fix this issue?
Thank you for another wonderful post. The place else may anybody get that type of info in such a perfect means of writing?
I’ve a presentation next week, and I’m on the look for such info.How to make
money online?
copy trade cryptocurrency successful
trades of traders in copy binary options and copy crypto trading.
From 100% to 1000% per month can reach your income.
I delight in, lead to I found exactly what I used to be having a look for.
You have ended my 4 day lengthy hunt! God Bless you man. Have a nice day.
Bye
Howdy! This post couldn’t be written much better!
Looking at this article reminds me of my previous roommate!
He always kept preaching about this. I most certainly will send this post
to him. Pretty sure he’ll have a good read. Thanks for sharing!
Magnificent goods from you, man. I have keep in mind your stuff previous to and you’re simply extremely excellent.
I really like what you’ve obtained right
here, really like what you are saying and the way
in which during which you are saying it. You
make it enjoyable and you continue to care for to stay it smart.
I can not wait to learn much more from you. This is really a tremendous web site.How to make money
online?
Copy successful trades of traders in copy binary options and
copy crypto trading.
From 100% to 1000% per month can reach your income.
Feel free to surf to my page binary option
Your website is very useful, thank you for your interest, I will visit it regularly.
Your website content is very useful, thank you for sharing it with us.
thanks post
Your website content is very useful, thank you.